编者按:为我国语言文字标准化、普通话推广、通用规范汉字和汉语拼音方案的推广普及方面做出重要贡献的傅永和先生,于2024年11月29日因病去世,享年83岁。今天,我们转发“韩玉堂”公众号文章(转发时有改动),以此纪念傅永和先生。

傅永和(1941-2024),历任中国文字改革委员会汉字处处长,国家语委秘书长、副主任,教育部语言文字信息司司长,国家督学,国家语委咨询委员会委员,曾主编、编著多种语言规范化、信息化书籍,如《汉字属性字典》《现代应用文体及经典范例全书》《简繁正异辨析字典》《汉字演变文化源流》《中文信息处理》等。主持制定《现代汉语常用字表》《现代汉语通用字表》等多种语言文字规范,推动《信息交换用 汉字编码字符集》《信息交换用 汉字点阵字模集和数据集》等多个系列的国家标准,推动《国家通用语言文字法》的编制和颁布。这些工作极大地推动了我国的语言文字标准化、规范化和信息化发展。
傅先生部分著作
01.《汉字属性字典》

1989 年 9 月由语文出版社出版,该书对 6763 个汉字的属性进行了系统梳理和详细标注,涵盖结构、读音、笔画等多种属性,其目的在于为汉字的教学、研究以及信息处理等提供全面、准确的参考依据。
02.《简繁正异辨析字典》

1995 年由辽宁教育出版社出版,该书对汉字的简繁、正异等属性进行了系统梳理和详细辨析,收入了众多非一一对应简繁字,有助于读者准确理解和把握汉字在不同形态下的差异,解决汉字使用中因简繁、正异字形相近或用法混淆而产生的问题,对汉字的规范化使用、教学研究以及文化传承等均有重要意义。
03.《汉字演变文化源流》

2012 年 12 月由广东教育出版社出版,该书从大文化背景对汉字演变深入研究,以字立篇目,从《说文》始,先出字形,后正读音,着力梳理汇集汉字演变历史,阐释其文化内涵和发展脉络,在内容、结构和体系上有创新突破,具有丰厚的学术底蕴和文化积累价值。
04.《中文信息处理》

1999 年由广东教育出版社出版,该书系统地阐述了中文信息处理的相关内容,对中文在计算机中的输入、存储、处理、输出等技术环节及相关理论进行了全面讲解,为推动中文信息处理技术的发展与应用提供了重要参考,对于相关专业的学生、研究人员以及从事中文信息处理工作的人员具有较高的学习和研究价值。
傅先生论语言规划
中文信息处理包括汉语言文字信息处理和少数民族语言文字信息处理。本文只讲汉语言文字信息处理。
一、中文信息处理奠基工程
1.汉字输入
古老的汉字进入计算机,这曾经是一个“科学的梦”。从20世纪50年代以来,国际国内的许多科学工作者,为了实现这个“科学的梦”,呕心沥血,潜心钻研于汉字编码事业。20世纪70年代中期,国务院副总理方毅批示:解决汉字进入计算机的问题,由中国文字改革委员会(国家语委前身)负责。1978年12月,由中国文字改革委员会和中国科技情报所在青岛召开“汉字编码学术研讨会”,有近百名汉字编码研究者与会。会议提出“破除迷信,解放思想,为彻底解决汉字进入计算机而努力奋斗”的口号,自此,掀起了汉字编码研究的高潮。此后,一大批实用的汉字键盘输入系统获得国内外发明专利,并在不同领域得到推广应用。这一事实震惊了国人、震惊了世界,对在中华大地普及计算机应用、推动信息技术革命,立下了不可磨灭的历史功绩!
2.汉字交换码
1979年春,中国文字改革委员会、电子工业部和国家标准局组织有关专家研究、编制计算机汉字交换码问题。经过集中攻关,按照国际标准的要求,研制出了国家标准《信息交换用汉字编码字符集·基本集》。该标准于1980年3月发布实施。目前广泛用于我国通用系统的信息交换及硬、软件设计中。如汉字字模库设计、汉字输入码的转换、汉字输出设备的汉字地址码等都遵照该标准进行设计。
3.汉字输出
利用计算机通用键盘输出汉字,计算机不能把汉字直接按汉字的一笔一画地输出,必须把汉字的每个笔划都变成密集的有数据的点才能输出,即在若干条等距离垂直线和水平线交叉形成的栅格内将汉字的笔划用点的形式描出,然后利用计算机辅助设计的方法,在一台通用汉字终端屏幕上用造字软件先画出放大的栅格,通过键盘严格按事前设计的点阵字模一笔一画地在栅格内打点、画线,计算机及时地把这些点、线转换成数据存入。经过上述处理后,计算机就可以实现汉字显示或打印输出了。
1980年,中国文字改革委员会和国家标准局组织相关单位联合攻关,经过近五年的努力,终于解决了计算机汉字输出问题,于1985年发布了国家标准《信息交换用汉字15×16点阵(宋体)字模集及数据集》。
上述奠基工程的完成,为计算机在社会各个领域中的广泛应用,奠定了坚实的基础。
二、汉字识别
汉字识别就是用计算机自动识别印刷或写在纸等介质上的汉字。汉字识别分为印刷体汉字识别和手写汉字识别两类。
印刷体汉字识别又分为两种。一种是单一印刷体汉字识别(一般为印刷宋体),一种是多种印刷体汉字识别(一般为印刷宋体、仿宋体、黑体、楷体)。
手写汉字识别分为联机手写汉字识别、手写印刷体汉字识别、特定人手写汉字识别三种。
目前,印刷体汉字识别已从纸介质印刷文档识别,扩展到计算机芯片、车牌、集装箱、视频中的汉字识别,识别率达99%以上,已完全商用。
联机手写汉字识别,其中工整有限自由书写,识别率达97%~99%;完全自由书写,识别率还比较低。当今,手机、平板电脑等设备上采用联机手写汉字识别。
脱机手写汉字识别,因没有书写的时序信息,识别难度大,识别率达92%左右。现用于银行票据、邮政分拣、物流包裹等。
汉字的笔画分为平笔和曲折笔。平笔又称为单笔笔画,如一、㇀、丨、丿、丶。折笔因有折点,又称为复合笔画。复合笔画根据折点多少分为单折点(一个折点)笔画和复折点(两个或两个以上折点)笔画。联机手写汉字识别,在识别复合笔画时,需根据折点前、后笔画的方向变化来判别,即根据笔段的方向值识别复合笔画。笔段的方向值如下图:

据上述笔段方向值,
乙
这一复合笔画的笔段方向值为2520;
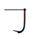
的笔段方向值为257;

的笔段方向值为25257;
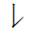
的笔段方向值为41,
等等。
三、语音识别
语音识别是指计算机能够确认和辨认发话者及其所讲语音内容,并以文字或语音记录、处理,与发话者会话。
汉语语音识别的类型有:按使用人分类,有特定人语音识别和非特定人语音识别;按词汇量分类,有小词汇量语音识别、中词汇量语音识别和大词汇量语音识别;按发音方式分类,有孤立词语语音识别和连续语音识别。
汉语语音识别从识别对象看,经历了特定人语音识别→非特定人语音识别两个阶段;从识别词汇量看,经历了小词汇量→中词汇量→大词汇量→海量词汇量四个阶段;从识别语种看,经历了单语种语音识别→多语种语音识别两个阶段;从声学环境看,经历了安静实验室环境→平稳噪声环境→复杂噪声环境三个阶段;从识别技术看,经历了音素识别→音节识别→单词识别→连接词识别→连续语音识别五个阶段。
总的来讲,语音识别由朗读式语音识别发展到现实生活中的“真实语言”语音识别,如新闻采访语音、报告讲座、电话语音、会议语音等。其中,电话交谈语音,因信道噪声恶劣、口语现象严重、说话人混叠现象突出等因素,识别难度大。目前,自然式电话对话语音识别率达80%左右。因此,自然语音识别面临着大的挑战。
1.说话人语音识别
说话人语音识别包括说话人辨识和说话人确认。
说话人辨识是从说话人集合中判别出测试语音所属的说话人。说话人确认是判断测试语音是否由目标说话人所说。
说话人语音识别已应用于公安司法领域。如对于电话勒索、绑架、电话人身攻击等案件,说话人辨认技术可以在一段录音中查找出嫌疑人,或缩小侦察范围。
2.语种识别
世界上有60亿人口,使用3000多种语言,64%的人口使用14种语言,语种识别有很强的应用价值。如航空、航海的紧急呼救语音信号,经过语种识别系统可以快速查找出是什么语言,防止因语言障碍而延误救援。此外,国防安全中的通信电话监听,语种识别系统可以做到真正的密切、准确监控,节省大量的人力和时间。
3.语音识别的社会应用
(1) 语音识别用于智能语音家电、智能车载语音服务。用于智能语音家电,如智能电视,可甩掉遥控器,实现语音搜索、语音遥控、语音解答、语音翻页等。用于智能车载语音识别系统,可以口述电子邮件、短信,口头设置导航目的地,口头进行一般的互联网搜索等。
(2) 用于语言学习和评测。随着信息技术的发展,语言教学和学习模式发生了巨大的变化。传统的“教室语言教学模式”难以满足语言学习,特别是第二语言学习的需要。语言学习已从传统的语法学习转向了更加注重交流能力的培养,语言学习越来越强调发音的学习和训练(发音是相互交流的基础)。计算机利用语音识别建立的辅助语言教学系统,具有用户语音与标准音对比功能,能诊断出用户语音与标准音的细节差异,从而有利于学习者学习。
语音评测涉及语音识别、自然语言理解、人工智能、数据挖掘、机器学习等多学科知识。目前,语音评测技术已经达到较高的评测信度,达到了人工评分的水平。衡量口语水平,除考察发音标准程度、流利程度、语调节奏之外,还应考察对话交流以及较长篇幅文章的观点表述能力。由于目前语义理解技术的限制,对给定主题的自由表达还不能做到完全自动评测。
四、汉语自然语言理解
人们按照计算机的特殊需要而设计的计算机语言,习惯上称之为“人工语言”。为了与人工语言相区别,习惯上把人际间的交际语言称之为自然语言。
自然语言理解就是研究如何利用计算机分析、理解和生成自然语言的理论和方法。自然语言理解是个极其复杂的研究课题,是一门自然科学和社会科学交叉的学科,涉及计算机科学、数学、语言学、心理学、哲学等学科。
自然语言理解的研究从20世纪50年代开始到70年代,基本上停留在实验室阶段,是纯理论的探讨。到了80年代才有突破性进展。目前,汉语理解取得了很多成果,在国际上处于领先地位。
自然语言理解的难点是:
1.至今尚未揭示出人类理解自然语言的机制,只能从功能上局部地模拟人类对自然语言的使用和理解。
2.人理解语言是凭借其全部知识并借助语言环境来体会和联想的,而要让计算机学会语言学知识、推理知识等是比较困难的,因为至今尚未形成知识表达的完整理论,即对人头脑中知识的形成及存储结构等机制还没有弄得很清楚。
3.自然语言是一个开放性的大系统,语言现象十分丰富,它既具有规则性又具有离散性,既具有精准性又具有模糊性,如何将这些教给计算机是相当困难的。
上述三点是各种语言计算机理解面临的共同困难。
汉语有自己的特点,计算机汉语理解还面临一些特殊的问题:
1. 汉语中同音字、同音词的存在,给语音识别和理解造成困难。
2. 汉语亲属称谓词最多,常用的亲属称谓词有 60 多种,而英语常用的称谓词才十几种,这给外汉机器翻译中的对译带来麻烦。
3. 汉语同义词极其丰富,若要计算机来区分、 理解同义词间的细微差别则比较困难。
4. 语量词特别丰富,而且有固定搭配;数量词与名词的位置可前可后。这种复杂情况是外汉机器翻译及汉语生成和篇章生成时的一个突出难点。
5. 汉语是词根语,采用连续书写形式,词与词之间没有自然界限,计算机理解汉语时首先要切分词,而汉语既无词尾形式标记,又无形态变化,计算机切分词的有用信息少,造成计算机自动分词难度较大。计算机自动分词是中文信息处理领域中继汉字编码输入计算机之后的又一瓶颈问题。汉语书面语不像西文那样是分词连写的,词与词之间没有明显的界限,进入计算机后,仍然是等距离排列的汉字字串序列。然而,在中文信息处理的许多领域中,如机器翻译、自然语言理解、文献检索、词频统计等语言工程中,都要求在词这一平面上进行处理。因此,必须用计算机自动地将等距离排列的汉字字串序列按词切分开来,打上切分标志。
计算机汉语自动分词过程中存在的问题很多,主要问题是歧义切分和未登录词识别,两者是分词精度失落的两大因素。而未登录词(人名、地名、机构名等命名实体及日期、时间等)造成的精度失落是歧义切分造成精度失落的五倍以上。
目前,计算机汉语自动分词由“先分词后理解”发展成“先理解后分词”,使歧义消解达到了最佳效果。另外,由“基于词(词典)的分词系统”发展成“基于字标注的分词系统”(字包括外文字母、阿拉伯数字、标点符号等),大大提高了分词精度。

 当前位置:
当前位置: